Building HTTP 2 server in Python
Python Twisted will support HTTP 2 in its web server.
HTTP2 is not available by default, to get it you need to install hyper-h2
(just runpip install twisted[h2]). This is really big and exciting news for whole Python ecosystem
so it’s worth seeing how it works and how difficult or easy it is to set up.
In this post I’m going to build some simple Twisted website serving content over HTTP 2 and then create a client connecting to this sample site. Will there be any big difference in performance between HTTP 2 and HTTP 1.1? Will my demo site work quicker in HTTP2?
Hello HTTP2
Let’s start with saying “Hello world!” in HTTP 2 from Python Twisted.
Twisted web server already supports Python 3 so you can use 3 no problem.
For this blog post I’m going to use Python 3.4.3. I’m assuming you have Twisted 16.3.0 with all
HTTP2 dependencies installed. There is some minor bug in parsing optional dependencies in Python 3, so
if you’re using 3 you may need to install “h2” and “priority” packages
from pip manually instead of running pip install twisted[h2].
Our website will serve content over HTTPS. While HTTP2 protocol itself does not require TLS, most client implementations (especially mainstream browsers) do require HTTPS. This means we need to start building our website with getting self signed certificates for local development. To generate self signed certificate you need to run following command:
# generate private key
$ openssl genrsa > privkey.pem
# generate certificate that will be stored in cert.pem file
$ openssl req -new -x509 -key privkey.pem -out cert.pem -days 365 -nodesAfter running above command you’ll need to fill out some details about you. You can ignore most of it or set some fake values, but keep in mind that some clients will refuse to connect if common name is not set to host name. Remember to put “localhost” if openssl asks you about “common name”.
Now that we have our ssl certificates let’s build simple “hello world” Twisted resource serving HTTP2 over HTTPS.
Our resource will be really simplest possible and it will look like this:
class Index(Resource):
isLeaf = True
def render_GET(self, request):
return b"hello world (in HTTP2)"Above code creates simple resource that will handle all request to root of website.
We now need to tell Twisted to listen on some specific port and serve our resource there using TLS. To actually launch our site on connection speaking SSL we’ll use Twisted endpoints. Endpoints are the recommended approach to do SSL in Twisted. In the past you could use Twisted DefaultSSLContextFactory, but this API is going to be deprecated in future releases. Factory misses lots of SSL features, is insecure and it won’t work properly with HTTP 2.
Here’s how you properly create instance of https website in Twisted:
# create instance of our web resource Index is instance of twisted.web.Resource
site = server.Site(Index())
# specify port and certificate
endpoint_spec = "ssl:port=8080:privateKey=privkey.pem:certKey=cert.pem"
# create listening endpoint
server = endpoints.serverFromString(reactor, endpoint_spec)
# start listening serving site in specified way
server.listen(site)Full hello world example will look like this:
import sys
from twisted.web import server
from twisted.web.resource import Resource
from twisted.internet import reactor
from twisted.python import log
from twisted.internet import endpoints
class Index(Resource):
isLeaf = True
def render_GET(self, request):
return b"hello world (in HTTP2)"
if __name__ == "__main__":
log.startLogging(sys.stdout)
site = server.Site(Index())
endpoint_spec = "ssl:port=8080:privateKey=privkey.pem:certKey=cert.pem"
server = endpoints.serverFromString(reactor, endpoint_spec)
server.listen(site)
reactor.run()So now we have Twisted server that has some alleged HTTP 2 support, but how do we actually test it? Obviously we need some HTTP2 client. One such client is curl. Unfortunately by default curl does not come with HTTP2 support. To be able to use HTTP2 you need to install optional dependencies and compile from source passing flag telling curl2 to compile with HTTP2 support. This is nicely described here, or also here.
After installing curl you can test your website like this
# remember about passing certificate to curl (--cacert option)
> curl2 --http2 https://localhost:8080 -v --cacert cert.pem
...
Using HTTP2, server supports multi-use
* Connection state changed (HTTP/2 confirmed)
* TCP_NODELAY set
* Copying HTTP/2 data in stream buffer to connection buffer after upgrade: len=0
* Using Stream ID: 1 (easy handle 0x16b2bc0)
> GET / HTTP/1.1
> Host: localhost:8080
> User-Agent: curl/7.49.1
> Accept: */*You can see curl reports that it uses HTTP2 on connection level but then actual request part is HTTP 1.1. This is expected. HTTP2 does not change HTTP semantics, all HTTP verbs, headers etc is valid in HTTP2. Majority of HTTP2 happens on TCP connection level.
In your server logs you should see following messages:
> python hello.py
2016-07-27 13:20:16+0200 [-] Log opened.
2016-07-27 13:20:16+0200 [-] Site (TLS) starting on 8080
2016-07-27 13:20:16+0200 [-] Starting factory <twisted.web.server.Site object at 0x7f263f172e80>
2016-07-27 13:20:18+0200 [-] "-" - - [27/Jul/2016:11:20:18 +0000] "GET / HTTP/2" 200 22 "-" "curl/7.49.1"This line "-" - - [27/Jul/2016:11:20:18 +0000] "GET / HTTP/2" 200 22 "-" "curl/7.49.1"
tells you that server used HTTP 2 when responding to curl request.
Hello world in Chrome
Why did I use curl and not just plain browser such as Chrome? The problem is that Chrome is super restrictive in HTTP 2 support. Chrome requires all connections to use ALPN protocol negotiation. This is discussed in detail here and here. To support ALPN your system has to have OpenSSL version above 1.0.2. At the moment of writing vast majority of Linux systems dont have OpenSSL 1.0.2 installed. Only Ubuntu 16.04 comes with OpenSSL 1.0.2. If you’re on Linux Upgrading your OpenSSL system wide is not a trivial task. I’m not sure about Mac OS or Widows or other OS-es. I recommend you check your openssl version yourself, if it’s above 1.0.2 you’re good to go testing in Chrome. Otherwise I created simple Dockerfile here using Ubuntu 16.04 and installing all dependencies, there’s also associated makefile here that tells you how to build and run docker image.
Once you have all dependencies, you also need to make Chrome accept your fake self signed certificate. Steps how to accomplish this are described here
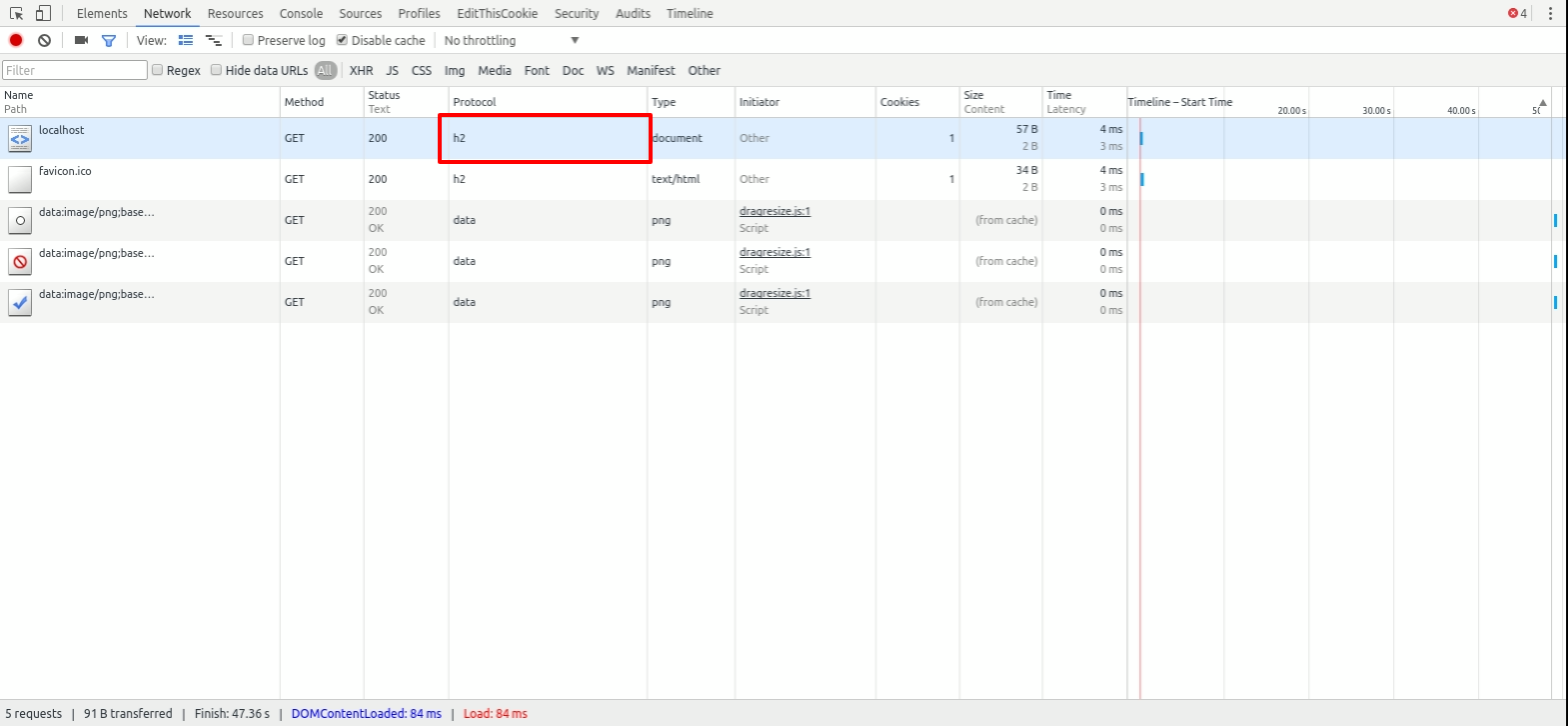
As you see making HTTP2 work in Chrome is not a trivial task. Once you’re ready you can test HTTP2 support by opening dev tools. Enabling ‘protocol’ column will allow you to see version of protocol used in connection, e.g. your dev tools should show something like this:
Benchmark HTTP2 vs HTTP1.1
Now that we know how to serve working (and secure) HTTP2 website with Twisted we can move to some more interesting things and compare differences between HTTP1.1 and HTTP2. Does it really matter if site is HTTP2 or HTTP1.1? Is there any real need to bother about HTTP2?
To try out things I’m going to build super simple online book store HTTP API. My book store will have 3000 science fiction books in store including classics by Ray Bradbury and Frank Herbert. I extracted data from goodreads.com with some trivial Scrapy project. You can download data from here. My bookstore will have initial page that lists all book ids in JSON. Each book will then have it’s own page where you can see some page details. Client will randomly first request index list and it will then visit each specific page to see what’s there. One client will parse HTTP1.1, other one will parse HTTP2. Which one will be quicker?
My API will look like this:
# server.py
import json
import sys
from twisted.web import server
from twisted.web.resource import Resource
from twisted.internet import reactor
from twisted.python import log
from twisted.internet import endpoints
def load_stock():
# load data from JSON
with open("books.json") as stock_file:
return json.load(stock_file)
BOOKS = load_stock()
class Index(Resource):
"""Serve all book ids.
"""
def render_GET(self, request):
return json.dumps(list(BOOKS.keys())).encode("utf8")
class Book(Resource):
"""Return detailed data about each book.
"""
isLeaf = True
def render_GET(self, request):
book_id = request.args.get(b"id")
book = BOOKS.get(book_id[0].decode("utf8"))
if not book:
request.setResponseCode(404)
return b""
return json.dumps(book).encode("utf8")
if __name__ == "__main__":
log.startLogging(sys.stdout)
root = Resource()
root.putChild(b"", Index())
root.putChild(b"book", Book())
site = server.Site(root)
endpoint_spec = "ssl:port=8080:privateKey=privkey.pem:certKey=cert.pem"
server = endpoints.serverFromString(reactor, endpoint_spec)
server.listen(site)
reactor.run()If you’d like to launch this server with me you can find all materials here
Now let’s see how HTTP1.1 client will perform when trying to crawl our SF bookstore. The client is going to be plain synchronous script using python-requests. It will first visit initial page with all book ids. After fetching all book ids it will request each book details page and read response. HTTP1.1 client will reuse one TCP connection. It will send ‘connection: keep-alive’ header and all requests will be send one after another within one TCP connection.
import json
import requests
s = requests.Session()
url = 'https://localhost:8080'
resp = s.get(url, verify="cert.pem")
index_data = json.loads(resp.text)
responses = []
for _id in index_data:
book_details_path = "/book?id={}".format(_id)
response = s.get(url + book_details_path, verify="cert.pem")
body = json.loads(response.text)
responses.append(body)
assert len(responses) == 3000Running above client on my test server produces following metrics:
User time (seconds): 4.09
System time (seconds): 0.15
Percent of CPU this job got: 72%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:05.84This means that client needed around 5 seconds to process our sf website.
Now let’s try HTTP2 client. In essence it will do same thing as HTTP1.1 client, it will connect to initial index page, fetch all books ids and request one book after another. The only difference is that the client will use HTTP2 multiplexing. This means that instead of sending requests one after another and waiting for responses we’ll send multiple requests at once and then we’ll fetch responses. HTTP 1.1 allows you to reuse TCP connection but the process is:
==== start connection ====
send request 1 --> wait for response --> receive response 1 --> send request 2 ...
==== end connection ====from what I understand in HTTP2 the process is more like
==== start connection ====
send request 1, send request 2, send request 3 --> wait for responses --> receive response 1, 2, 3
==== end connection ====In HTTP1.1 if you have one slow response it will block connection. In HTTP2 you can send multiple requests to your server over one connection at the same time and then fetch responses as they arrive from origin.
To use HTTP2 to its full capabilities our client is going to send multiple requests over one connection and then fetch responses. It will split initial list of 3000 books into chunks of 100 urls. For every chunk it will start with sending 100 requests. In next step it will iterate over connection stream ids and fetch responses.
I’m going to use python-hyper as underlying client library. Twisted does not yet support HTTP2 client side, but work on supporting it is in progress.
import json
from hyper import HTTPConnection
conn = HTTPConnection('localhost:8080', secure=True)
conn.request('GET', '/')
resp = conn.get_response()
# process initial page with book ids
index_data = json.loads(resp.read().decode("utf8"))
responses = []
chunk_size = 100
# split initial set of urls into chunks of 100 items
for i in range(0, len(index_data), chunk_size):
request_ids = []
# make requests
for _id in index_data[i:i+chunk_size]:
book_details_path = "/book?id={}".format(_id)
request_id = conn.request('GET', book_details_path)
request_ids.append(request_id)
# get responses
for req_id in request_ids:
response = conn.get_response(req_id)
body = json.loads(response.read().decode("utf8"))
responses.append(body)
assert len(responses) == 3000What kind of performance can we expect from HTTP2 client?
User time (seconds): 1.41
System time (seconds): 0.04
Percent of CPU this job got: 41%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:03.53To sum up HTTP2 client is faster, but it also works slightly differently. If you were to use HTTP2 in same way as HTTP1.1 (just send one request after another within one connection) performance difference would be small or non-existent. It’s also worth noting that I didnt go into details of other HTTP2 improvements (such as headers compression or server push). These other benefits of HTTP2 are certainly equally important as multiplexing of messages over one connection. I’m not sure if you can use server push from Twisted though.